ResNet
ResNet 引入
在VGG-19中,卷积网络达到了 19 层,在GoogLeNet中,网络史无前例的达到了 22 层。
网络层数越高包含的函数空间也就越大,理论上网络的加深会让模型更有可能找到合适的函数。
但实际上,网络的精度会随着网络的层数增多而增多吗?在深度学习中,网络层数增多一般会伴着下面几个问题
- 计算资源的消耗
- 模型容易过拟合
- 梯度消失/梯度爆炸问题的产生
根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
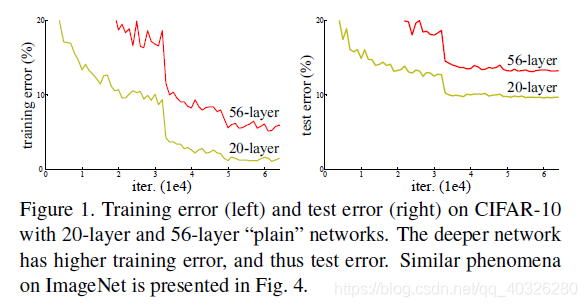
作者发现,随着网络层数的增加,网络发生了退化(degradation)的现象:随着网络层数的增多,训练集 loss 逐渐下降,然后趋于饱和,当你再增加网络深度的话,训练集 loss 反而会增大。注意这并不是过拟合,因为在过拟合中训练 loss 是一直减小的。
当网络退化时,浅层网络能够达到比深层网络更好的训练效果,这时如果我们把低层的特征传到高层,那么效果应该至少不比浅层的网络效果差,或者说如果一个 VGG-100 网络在第 98 层使用的是和 VGG-16 第 14 层一模一样的特征,那么 VGG-100 的效果应该会和 VGG-16 的效果相同。所以,我们可以在 VGG-100 的 98 层和 14 层之间添加一条直接映射(Identity Mapping)来达到此效果。
从信息论的角度讲,由于 DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map 包含的图像信息会逐层减少,而 ResNet 的直接映射的加入,保证了 $l+1$ 层的网络一定比 $l$ 层包含更多的图像信息。
基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生。
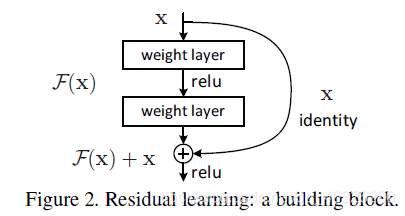
ResNet 是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于 VLAD(残差的想法来源)和 Highway Network(跳跃连接的想法来源)。
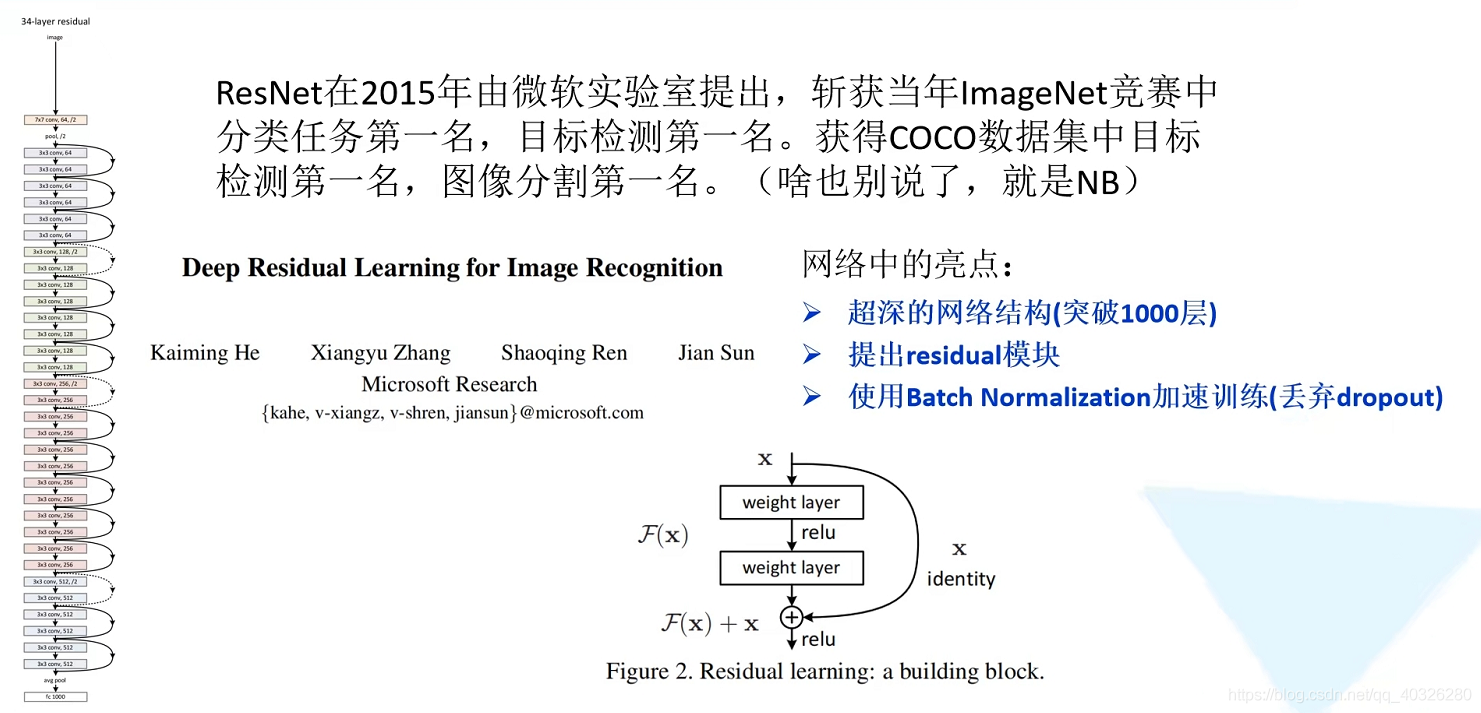
ResNet 结构
1 | import tensorflow as tf |
定义 BasicBlock 和 Bottleneck(ResNet50/101/152)
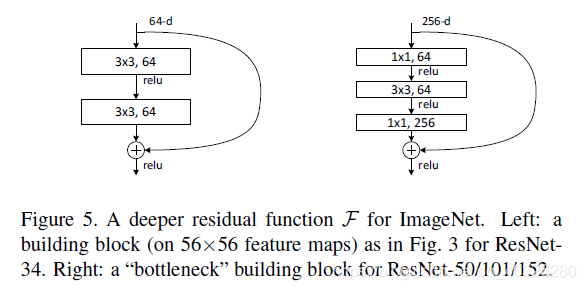
1 | class BasicBlock(layers.Layer): |
1 | class Bottleneck(layers.Layer): # 瓶颈 两边粗中间细 |
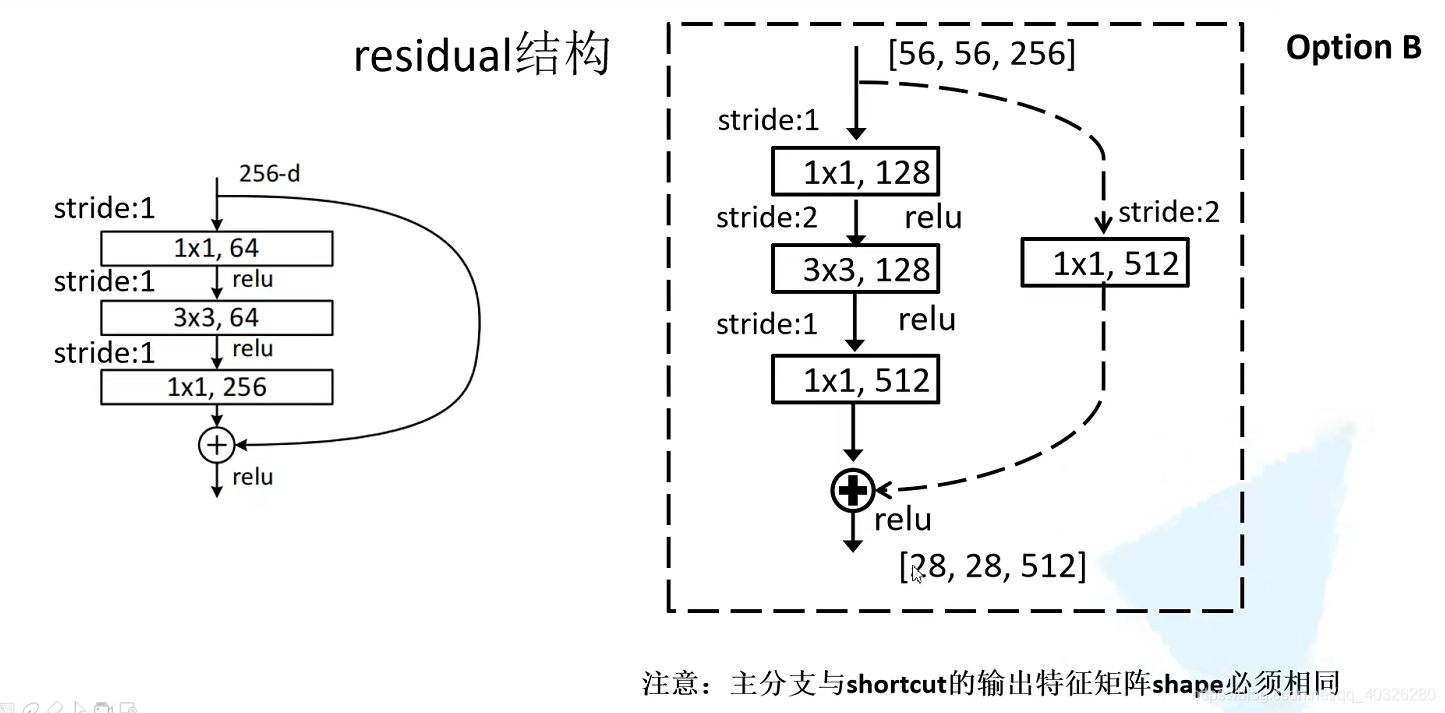
在 block 之间衔接处,由于 feature map 的尺寸不一致,所以需要进行下采样的操作。论文中是通过$1\times 1 , strides=2$的卷积实现的。
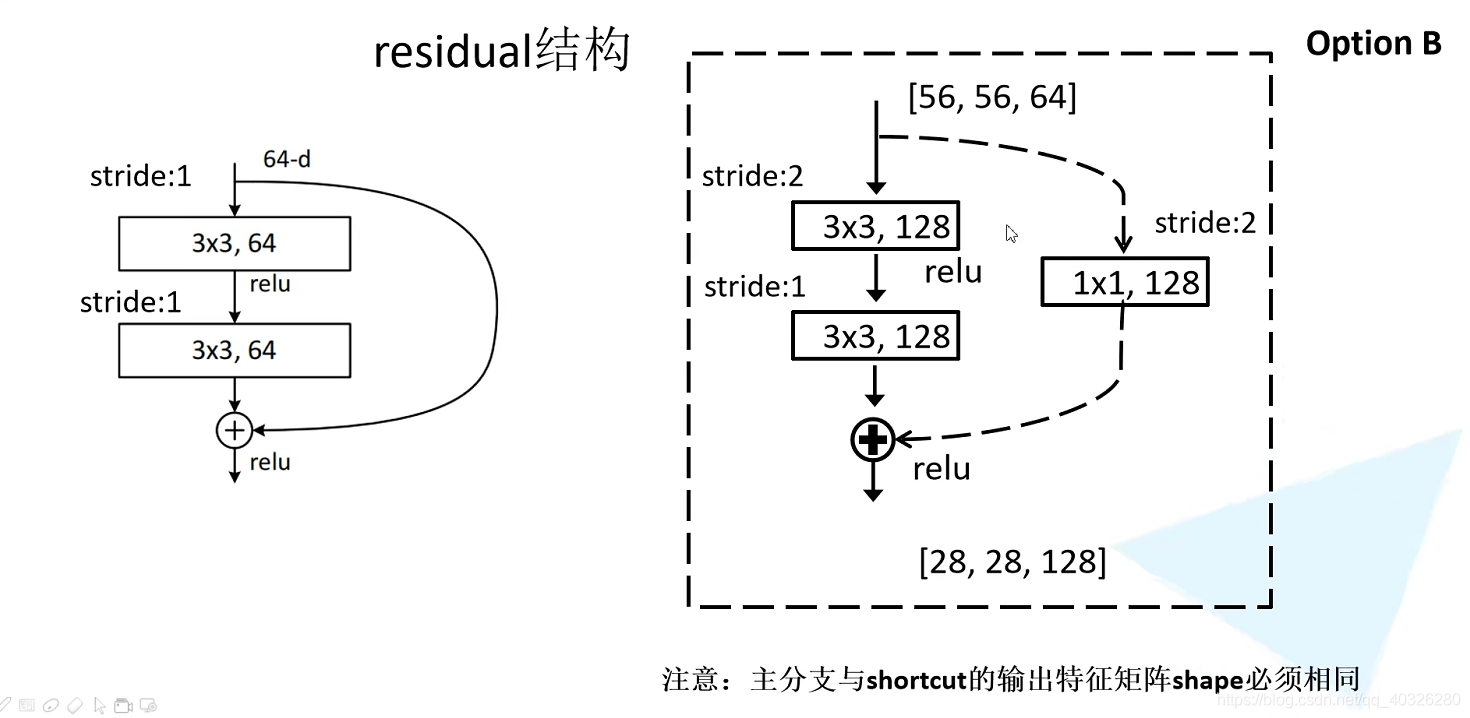
在 resnet50/101/152 中结构稍微有一些不同
1 | class ResNet(Model): |
resnet_block_v2
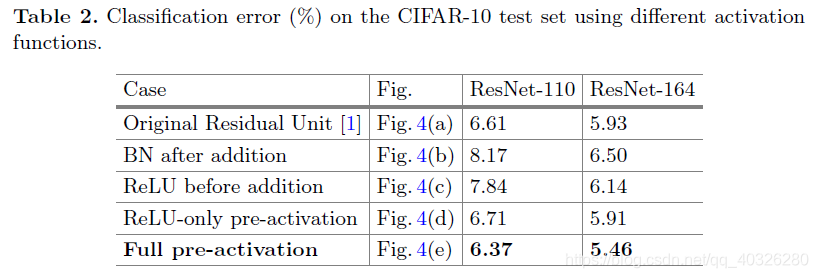
最初的 resnet 残差块可以详细展开如Fig.4(a),即在卷积之后使用了 BN 做归一化,然后在和直接映射单位加之后使用了 ReLU 作为激活函数。
Fig.4(c)反应到网络里即将激活函数移到残差部分使用,这种在卷积之后使用激活函数的方法叫做 post-activation。然后,作者通过调整 ReLU 和 BN 的使用位置得到了几个变种,即Fig.4(d)中的 ReLU-only pre-activation 和Fig.4(e)中的 full pre-activation。
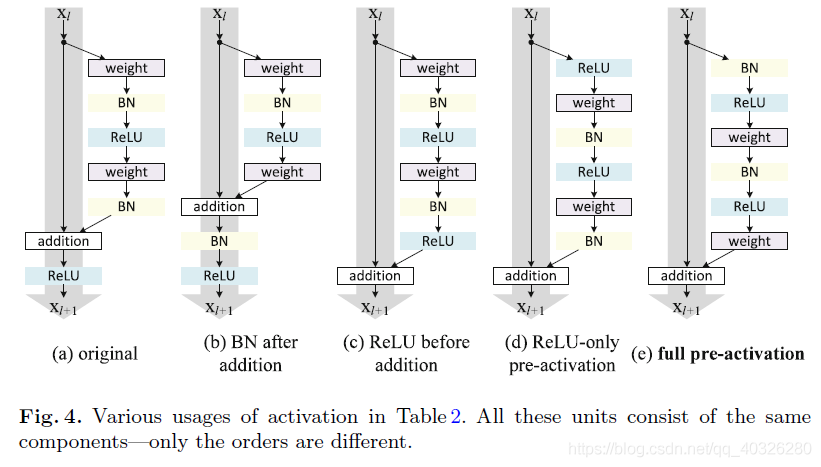
作者通过对照试验对比了这几种变异模型,结果见Tabel 2。
搭建 resnet_block_v2
1 | # (e)full pre-activation |
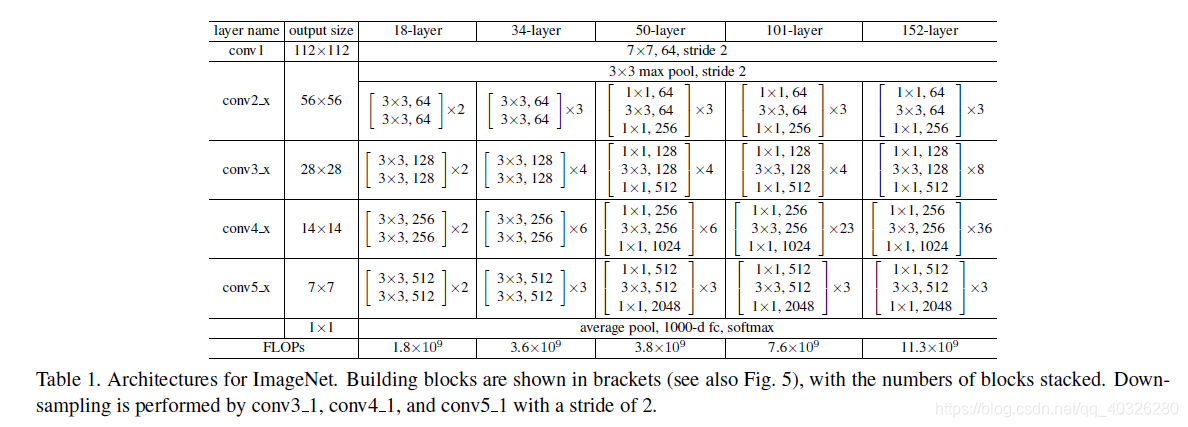
下面定义了 resnet_v1 版本 34/50/101 三种深度的网络模型:
1 | def resnet_34(num_classes=1000, include_top=True): |
下面定义了 resnet_v2 版本 34/50/101 三种深度的网络模型:
1 | def resnet_v2_34(num_classes=1000, include_top=True): |
主函数模型测试部分(每个实测通过):
1 | def main(): |
1 | Model: "res_net_21" |



