交叉熵(Cross Entropy)
[toc]
交叉熵(cross entropy)是深度学习中常用的一个概念,一般用来求目标与预测值之间的差距。
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。语言模型的性能通常用交叉熵和复杂度(perplexity)来衡量。交叉熵的意义是用该模型对文本识别的难度,或者从压缩的角度来看,每个词平均要用几个位来编码。复杂度的意义是用该模型表示这一文本平均的分支数,其倒数可视为每个词的平均概率。平滑是指对没观察到的 N 元组合赋予一个概率值,以保证词序列总能通过语言模型得到一个概率值。通常使用的平滑技术有图灵估计、删除插值平滑、Katz 平滑和 Kneser-Ney 平滑。
信息论
在信息论中,交叉熵是表示两个概率分布 p,q,其中 p 表示真实分布,q 表示非真实分布,在相同的一组事件中,其中,用非真实分布 q 来表示某个事件发生所需要的平均比特数。从这个定义中,我们很难理解交叉熵的定义。下面举个例子来描述一下:
假设现在有一个样本集中两个概率分布 p,q,其中 p 为真实分布,q 为非真实分布。假如,按照真实分布 p 来衡量识别一个样本所需要的编码长度的期望为:
$$
H§ = \sum_i{p(i)\cdot log(\frac{1}{p(i)})}
$$
但是,如果采用错误的分布 q 来表示来自真实分布 p 的平均编码长度,则应该是:
$$
H(p, q) = \sum_i{p(i)\cdot log(\frac{1}{q(i)})}
$$
此时就将$H(p,q)$称之为交叉熵。
交叉熵的计算方式如下:
对于离散变量采用以下的方式计算:$H(p, q) = \sum_x{p(x)\cdot log(\frac{1}{q(x)})}$
对于连续变量采用以下的方式计算:$\int_X {P(X) log(Q(X)) dr(x)} = E_p[-logQ]$
相对熵
相对熵又称 KL 散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异。
维基百科中对相对熵的定义为:
In the context of machine learning, DKL(P‖Q) is often called the information gain achieved if P is used instead of Q.
即如果用 P 来描述目标问题,而不是用 Q 来描述目标问题,得到的信息增量。
在机器学习中,P 往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q 用来表示模型所预测的分布,比如[0.7,0.2,0.1]
直观的理解就是如果用 P 来描述样本,那么就非常完美。而用 Q 来描述样本,虽然可以大致描述,但是不是那么的完美,信息量不足,需要额外的一些“信息增量”才能达到和 P 一样完美的描述。如果我们的 Q 通过反复训练,也能完美的描述样本,那么就不再需要额外的“信息增量”,Q 等价于 P。
KL 散度的计算公式为:
$$
D_{KL}(p||q)=\sum_{i=1}^np(x_i)log(\frac{p(x_i)}{q(x_i)}) \tag{1}
$$
其中$n$为事件的所有可能性。$D_{KL}$的值越小,表示$q$分布和$p$分布越接近。
交叉熵
交叉熵可在神经网络(机器学习)中作为损失函数,p 表示真实标记的分布,q 则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量 p 与 q 的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
在特征工程中,可以用来衡量两个随机变量之间的相似度。
在语言模型中(NLP)中,由于真实的分布 p 是未知的,在语言模型中,模型是通过训练集得到的,交叉熵就是衡量这个模型在测试集上的正确率。
对相对熵计算式(1)进行变形可以得到:
$$
\begin{aligned}
D_{KL}(p||q)
&= \sum_{i=1}^np(x_i)log(p(x_i))-\sum_{i=1}^np(x_i)log(q(x_i)) \
&= -H(p(x))+ [-\sum_{i=1}^np(x_i)log(q(x_i))]
\end{aligned}
$$
等式的前一部分恰巧就是 p 的熵,等式的后一部分,就是交叉熵:
$$
H(p,q)=-\sum_{i=1}^n p(x_i)log(q(x_i))
$$
在机器学习中,我们需要评估label和predicts之间的差距,使用 KL 散度刚刚好,即$D_{KL}(y||\hat{y})$,由于 KL 散度中的前一部分$−H(y)$不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做 loss,评估模型。
机器学习中的交叉熵
为什么要用交叉熵做损失函数?
在线性回归问题中,常常使用MSE(Mean Squared Error)作为 loss 函数,比如:
$$
loss=\frac{1}{2m}\sum_{i=1}^m (y_i - \hat{y_i})^2
$$
其中 m 表示样本数,loss 为 m 个样本的 loss 均值。
MSE 在线性回归问题中比较好用,那么在逻辑分类问题中还是如此么?
分类问题中的交叉熵
单类别是指,每一张图像样本只能有一个类别,比如只能是狗或只能是猫。
在单类别问题中,交叉熵的计算如下:
$$
loss=-\sum_{i=1}^{n}y_ilog(\hat{y_i})
$$
假设label和pred的取值如下:
| cat | dog | man | |
|---|---|---|---|
| label | 1 | 0 | 0 |
| pred | 0.7 | 0.2 | 0.1 |
计算可得:
$$
Loss_crossEntropy = - (1\times log(0.7) + 0\times log(0.2) + 0\times log(0.1)) = -log(0.7)
$$
同理可得batch_loss:
$$
loss_batch=-\frac{1}{m}\sum_{j=1}^m\sum_{i=1}^{n}y_{ji}log(\hat{y_{ji}})
$$
如果label为多分类,即类别不互斥的情况下,交叉熵的计算如下:
$$
Loss_crossEntropy =-ylog(\hat{y})-(1-y)log(1-\hat{y})
$$
batch:
$$
loss_batch =\frac{1}{m} \sum_{j=1}^{m}\sum_{i=1}^{n}-y_{ji}log(\hat{y_{ji}})-(1-y_{ji})log(1-\hat{y_{ji}})
$$
softmax
由于做交叉熵之前一般都会用进行softmax处理,所以这里简单介绍一下softmax。
假设我们有一个数组$V$,$V_i$表示$V$中的第 i 个元素,那么这个元素的 Softmax 值就是
$$
S_i = \frac{e^{V_i}}{\sum_j{e^{V_j}}}
$$
也就是说,是该元素的指数,与所有元素指数和的比值。
softmax的过程如图所示:
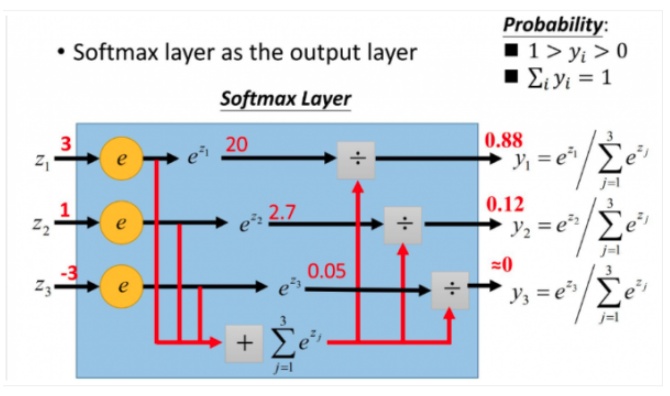
softmax 直白来说就是将原来输出是 3,1,-3 通过 softmax 函数一作用,就映射成为(0,1)的值,而这些值的累和为 1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
softmax_cross_entropy 求导
在多分类问题中,我们经常使用交叉熵作为损失函数:
$$
loss=-\sum_{i=1}^{n}y_ilog(\hat{y_i})
$$
当预测第 i 个时,$y$可以认为是 1,此时损失函数变成了:
$$
loss_i=-log(\hat{y_i})
$$
接下来对 Loss 求导。根据定义:
$$
y_i = \frac{e^i}{\sum_j{e^j}}
$$
由于 softmax 已经将数值映射到了 0-1 之间,并且和为 1,则有:
$$
\frac{e^i}{\sum_j{e^j}} = 1 - \frac{\sum_{i\neq j}e^i}{\sum_j{e^j}}
$$
下面是求导过程(结合链式法则):
$$
\begin{aligned}
\frac{\partial loss_i}{\partial _i}
&= - \frac{\partial lny_i}{\partial _i} \
&= - \frac{\sum_j{e^j}}{e^i} \frac{\partial}{\partial i}( \frac{e^i}{\sum_j{e^j}}) \
&= - \frac{\sum_j{e^j}}{e^i} \frac{\partial}{\partial i}( \frac{e^i}{\sum{j \neq i}{e^j} + e^i}) \
&= - \frac{\sum_j{e^j}}{e^i} \frac{e^i\sum_j e^j - {e^i}^2}{(\sum{j \neq i}{e^j} + e^i)^2} \
&= - \frac{\sum_j e^j - {e^i}}{\sum_j{e^j}} \
&= - (1 - \frac{e^i}{\sum_j{e^j}}) \
&= y_i - 1
\end{aligned}
$$
Python 实现单分类 softmax_交叉熵
通过以上理论我们就可以自己实现交叉熵函数,并与流行框架中的计算结果进行对比
1 | import numpy as np |
1 | my_softmax: |



