paddle2.0高层API实现基于seq2seq的对联生成
[toc]
『深度学习 7 日打卡营·day5』
零基础解锁深度学习神器飞桨框架高层 API,七天时间助你掌握 CV、NLP 领域最火模型及应用。
- 课程地址
传送门:https://aistudio.baidu.com/aistudio/course/introduce/6771
- 目标
- 掌握深度学习常用模型基础知识
- 熟练掌握一种国产开源深度学习框架
- 具备独立完成相关深度学习任务的能力
- 能用所学为 AI 加一份年味
对联,是汉族传统文化之一,是写在纸、布上或刻在竹子、木头、柱子上的对偶语句。对联对仗工整,平仄协调,是一字一音的汉语独特的艺术形式,是中国传统文化瑰宝。
这里,我们将根据上联,自动写下联。这是一个典型的序列到序列(sequence2sequence, seq2seq)建模的场景,编码器-解码器(Encoder-Decoder)框架是解决 seq2seq 问题的经典方法,它能够将一个任意长度的源序列转换成另一个任意长度的目标序列:编码阶段将整个源序列编码成一个向量,解码阶段通过最大化预测序列概率,从中解码出整个目标序列。编码和解码的过程通常都使用 RNN 实现。
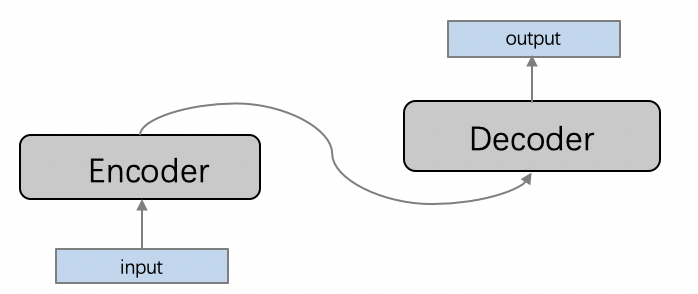
这里的 Encoder 采用 LSTM,Decoder 采用带有 attention 机制的 LSTM。
我们将以对联的上联作为 Encoder 的输出,下联作为 Decoder 的输入,训练模型。
生成对联部分结果
1 | 上联: 芳 草 绿 阳 关 塞 上 春 风 入 户 下联: 小 桥 流 水 人 家 中 喜 气 盈 门 |
AI Studio 平台后续会默认安装 PaddleNLP,在此之前可使用如下命令安装。
1 | !pip install --upgrade paddlenlp>=2.0.0b -i https://mirror.baidu.com/pypi/simple |
1 | import paddlenlp |
1 | '2.0.0rc1' |
1 | import io |
数据部分
数据集介绍
采用开源的对联数据集couplet-clean-dataset,该数据集过滤了
couplet-dataset中的低俗、敏感内容。
这个数据集包含 70w 多条训练样本,1000 条验证样本和 1000 条测试样本。
下面列出一些训练集中对联样例:
上联:晚风摇树树还挺 下联:晨露润花花更红
上联:愿景天成无墨迹 下联:万方乐奏有于阗
上联:丹枫江冷人初去 下联:绿柳堤新燕复来
上联:闲来野钓人稀处 下联:兴起高歌酒醉中
加载数据集
paddlenlp.datasets中内置了多个常见数据集,包括这里的对联数据集CoupletDataset。
paddlenlp.datasets均继承paddle.io.Dataset,支持paddle.io.Dataset的所有功能:
- 通过
len()函数返回数据集长度,即样本数量。 - 下标索引:通过下标索引[n]获取第 n 条样本。
- 遍历数据集,获取所有样本。
此外,paddlenlp.datasets,还支持如下操作:
- 调用
get_datasets()函数,传入 list 或者 string,获取相对应的 train_dataset、development_dataset、test_dataset 等。其中 train 为训练集,用于模型训练; development 为开发集,也称验证集 validation_dataset,用于模型参数调优;test 为测试集,用于评估算法的性能,但不会根据测试集上的表现再去调整模型或参数。 - 调用
apply()函数,对数据集进行指定操作。
这里的CoupletDataset数据集继承TranslationDataset,继承自paddlenlp.datasets,除以上通用用法外,还有一些个性设计:
- 在
CoupletDataset class中,还定义了transform函数,用于在每个句子的前后加上起始符<s>和结束符</s>,并将原始数据映射成 id 序列。
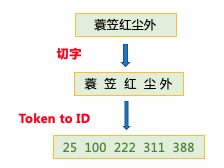
1 | train_ds, dev_ds, test_ds = CoupletDataset.get_datasets(['train', 'dev', 'test']) |
1 | 100%|██████████| 21421/21421 [00:00<00:00, 26153.43it/s] |
来看看数据集有多大,长什么样:
1 | print(len(train_ds), len(test_ds), len(dev_ds)) |
1 | 702594 999 1000 |
1 | vocab, _ = CoupletDataset.get_vocab() |
1 | 2 1 2 |
构造 dataloder
使用paddle.io.DataLoader来创建训练和预测时所需要的DataLoader对象。
paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回 dataset 数据。支持单进程或多进程加载数据,快!
接收如下重要参数:
batch_sampler:批采样器实例,用于在paddle.io.DataLoader中迭代式获取 mini-batch 的样本下标数组,数组长度与 batch_size 一致。collate_fn:指定如何将样本列表组合为 mini-batch 数据。传给它参数需要是一个callable对象,需要实现对组建的 batch 的处理逻辑,并返回每个 batch 的数据。在这里传入的是prepare_input函数,对产生的数据进行 pad 操作,并返回实际长度等。
PaddleNLP 提供了许多 NLP 任务中,用于数据处理、组 batch 数据的相关 API。
| API | 简介 |
|---|---|
paddlenlp.data.Stack |
堆叠 N 个具有相同 shape 的输入数据来构建一个 batch |
paddlenlp.data.Pad |
将长度不同的多个句子 padding 到统一长度,取 N 个输入数据中的最大长度 |
paddlenlp.data.Tuple |
将多个 batchify 函数包装在一起 |
更多数据处理操作详见: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/docs/data.md
1 | def create_data_loader(dataset): |
1 | use_gpu = True |
1 | 702594 5490 128 |
模型部分
下图是带有 Attention 的 Seq2Seq 模型结构。下面我们分别定义网络的每个部分,最后构建 Seq2Seq 主网络。
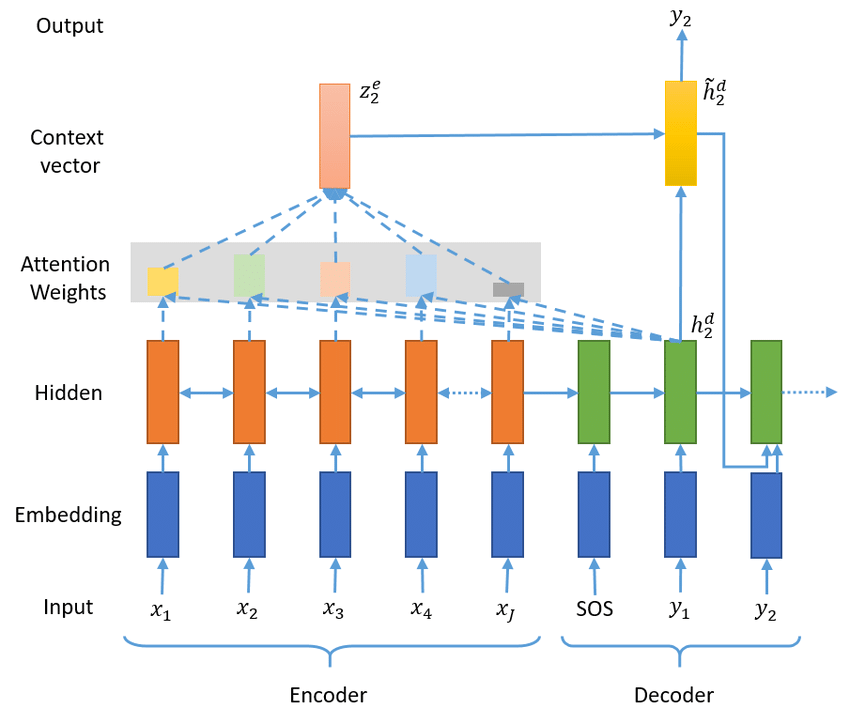
定义 Encoder
Encoder 部分非常简单,可以直接利用 PaddlePaddle2.0 提供的 RNN 系列 API 的nn.LSTM。
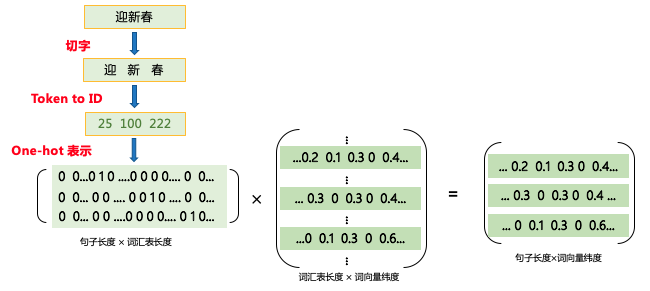
nn.Embedding:该接口用于构建 Embedding 的一个可调用对象,根据输入的 size (vocab_size, embedding_dim)自动构造一个二维 embedding 矩阵,用于 table-lookup。查表过程如下:
nn.LSTM:提供序列,得到encoder_output和encoder_state。
参数:
- input_size (int) 输入的大小。
- hidden_size (int) - 隐藏状态大小。
- num_layers (int,可选) - 网络层数。默认为 1。
- direction (str,可选) - 网络迭代方向,可设置为 forward 或 bidirect(或 bidirectional)。默认为 forward。
- time_major (bool,可选) - 指定 input 的第一个维度是否是 time steps。默认为 False。
- dropout (float,可选) - dropout 概率,指的是出第一层外每层输入时的 dropout 概率。默认为 0。
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/layer/rnn/LSTM_cn.html
输出:
-
outputs (Tensor)- 输出,由前向和后向 cell 的输出拼接得到。如果
time_major为 True,则 Tensor 的形状为[time_steps, batch_size, num_directions * hidden_size]如果
time_major为 False,则 Tensor 的形状为[batch_size, time_steps, num_directions * hidden_size],当 direction 设置为 bidirectional 时,num_directions 等于 2,否则等于 1。 -
final_states (tuple)- 最终状态,一个包含 h 和 c 的元组。形状为
[num_lauers * num_directions, batch_size, hidden_size],当 direction 设置为 bidirectional 时,num_directions 等于 2,否则等于 1。
1 | class Seq2SeqEncoder(nn.Layer): |
定义 Decoder
定义 AttentionLayer
nn.Linear线性变换层传入 2 个参数
- in_features (int) – 线性变换层输入单元的数目。
- out_features (int) – 线性变换层输出单元的数目。
paddle.matmul用于计算两个 Tensor 的乘积,遵循完整的广播规则,关于广播规则,请参考广播 (broadcasting) 。 并且其行为与 numpy.matmul 一致。
- x (Tensor) : 输入变量,类型为 Tensor,数据类型为 float32, float64。
- y (Tensor) : 输入变量,类型为 Tensor,数据类型为 float32, float64。
- transpose_x (bool,可选) : 相乘前是否转置 x,默认值为 False。
- transpose_y (bool,可选) : 相乘前是否转置 y,默认值为 False。
-
paddle.unsqueeze用于向输入 Tensor 的 Shape 中一个或多个位置(axis)插入尺寸为 1 的维度 -
paddle.add逐元素相加算子,输入 x 与输入 y 逐元素相加,并将各个位置的输出元素保存到返回结果中。
输入 x 与输入 y 必须可以广播为相同形状。
1 | class AttentionLayer(nn.Layer): |
定义 Seq2SeqDecoderCell
由于 Decoder 部分是带有 attention 的 LSTM,我们不能复用nn.LSTM,所以需要定义Seq2SeqDecoderCell
nn.LayerList用于保存子层列表,它包含的子层将被正确地注册和添加。列表中的子层可以像常规 python 列表一样被索引。这里添加了 num_layers=2 层 lstm。
1 | class Seq2SeqDecoderCell(nn.RNNCellBase): |
定义 Seq2SeqDecoder
有了Seq2SeqDecoderCell,就可以构建Seq2SeqDecoder了
paddle.nn.RNN该 OP 是循环神经网络(RNN)的封装,将输入的 Cell 封装为一个循环神经网络。它能够重复执行 cell.forward() 直到遍历完 input 中的所有 Tensor。
- cell (RNNCellBase) - RNNCellBase 类的一个实例。
1 | class Seq2SeqDecoder(nn.Layer): |
构建主网络 Seq2SeqAttnModel
Encoder 和 Decoder 定义好之后,网络就可以构建起来了
1 | class Seq2SeqAttnModel(nn.Layer): |
定义损失函数
这里使用的是交叉熵损失函数,我们需要将 padding 位置的 loss 置为 0,因此需要在损失函数中引入trg_mask参数,由于 PaddlePaddle 框架提供的paddle.nn.CrossEntropyLoss不能接受trg_mask参数,因此在这里需要重新定义:
1 | class CrossEntropyCriterion(nn.Layer): |
执行过程
训练过程
使用高层 API 执行训练,需要调用prepare和fit函数。
在prepare函数中,配置优化器、损失函数,以及评价指标。其中评价指标使用的是 PaddleNLP 提供的困惑度计算 API paddlenlp.metrics.Perplexity。
如果你安装了 VisualDL,可以在 fit 中添加一个 callbacks 参数使用 VisualDL 观测你的训练过程,如下:
1 | model.fit(train_data=train_loader, |
在这里,由于对联生成任务没有明确的评价指标,因此,可以在保存的多个模型中,通过人工评判生成结果选择最好的模型。
本项目中,为了便于演示,已经将训练好的模型参数载入模型,并省略了训练过程。读者自己实验的时候,可以尝试自行修改超参数,调用下面被注释掉的fit函数,重新进行训练。
如果读者想要在更短的时间内得到效果不错的模型,可以使用预训练模型技术,例如《预训练模型 ERNIE-GEN 自动写诗》项目为大家展示了如何利用预训练的生成模型进行训练。
1 | model = paddle.Model(Seq2SeqAttnModel(vocab_size, hidden_size, hidden_size, num_layers, pad_id)) |
1 | The loss value printed in the log is the current step, and the metric is the average value of previous step. |
模型预测
定义预测网络 Seq2SeqAttnInferModel
预测网络继承上面的主网络Seq2SeqAttnModel,定义子类Seq2SeqAttnInferModel
1 | class Seq2SeqAttnInferModel(Seq2SeqAttnModel): |
解码部分
接下来对我们的任务选择 beam search 解码方式,可以指定 beam_size 为 10。
1 | def post_process_seq(seq, bos_idx, eos_idx, output_bos=False, output_eos=False): |
1 | beam_size = 10 |
在预测之前,我们需要将训练好的模型参数 load 进预测网络,之后我们就可以根据对联的上联,生成对联的下联啦!
1 | model.load('couplet_models/final') |
1 | test_ds = CoupletDataset.get_datasets(['test']) |
PaddleNLP 更多教程
- 使用 seq2vec 模块进行句子情感分析
- 使用预训练模型 ERNIE 优化情感分析
- 使用 BiGRU-CRF 模型完成快递单信息抽取
- 使用预训练模型 ERNIE 优化快递单信息抽取
- 使用预训练模型 ERNIE-GEN 实现智能写诗
- 使用 TCN 网络完成新冠疫情病例数预测
- 使用预训练模型完成阅读理解
- 自定义数据集实现文本多分类任务
加入交流群,一起学习吧
现在就加入 PaddleNLP 的 QQ 技术交流群,一起交流 NLP 技术吧!




