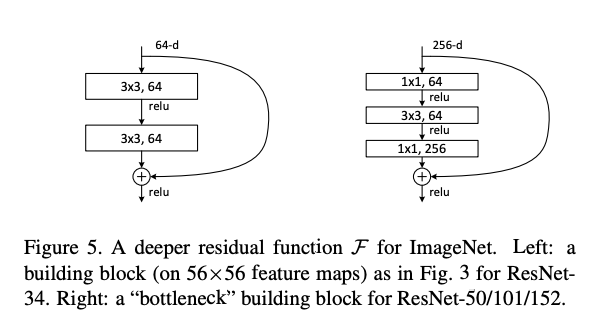
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
| 100%|██████████| 20795/20795 [00:00<00:00, 44614.48it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1263: UserWarning: Skip loading for classifier.1.weight. classifier.1.weight receives a shape [1280, 1000], but the expected shape is [1280, 12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1263: UserWarning: Skip loading for classifier.1.bias. classifier.1.bias receives a shape [1000], but the expected shape is [12].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-160 [[1, 3, 224, 224]] [1, 32, 112, 112] 864
BatchNorm2D-107 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU6-1 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-161 [[1, 32, 112, 112]] [1, 32, 112, 112] 288
BatchNorm2D-108 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU6-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-162 [[1, 32, 112, 112]] [1, 16, 112, 112] 512
BatchNorm2D-109 [[1, 16, 112, 112]] [1, 16, 112, 112] 64
InvertedResidual-1 [[1, 32, 112, 112]] [1, 16, 112, 112] 0
Conv2D-163 [[1, 16, 112, 112]] [1, 96, 112, 112] 1,536
BatchNorm2D-110 [[1, 96, 112, 112]] [1, 96, 112, 112] 384
ReLU6-3 [[1, 96, 112, 112]] [1, 96, 112, 112] 0
Conv2D-164 [[1, 96, 112, 112]] [1, 96, 56, 56] 864
BatchNorm2D-111 [[1, 96, 56, 56]] [1, 96, 56, 56] 384
ReLU6-4 [[1, 96, 56, 56]] [1, 96, 56, 56] 0
Conv2D-165 [[1, 96, 56, 56]] [1, 24, 56, 56] 2,304
BatchNorm2D-112 [[1, 24, 56, 56]] [1, 24, 56, 56] 96
InvertedResidual-2 [[1, 16, 112, 112]] [1, 24, 56, 56] 0
Conv2D-166 [[1, 24, 56, 56]] [1, 144, 56, 56] 3,456
BatchNorm2D-113 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-5 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-167 [[1, 144, 56, 56]] [1, 144, 56, 56] 1,296
BatchNorm2D-114 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-6 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-168 [[1, 144, 56, 56]] [1, 24, 56, 56] 3,456
BatchNorm2D-115 [[1, 24, 56, 56]] [1, 24, 56, 56] 96
InvertedResidual-3 [[1, 24, 56, 56]] [1, 24, 56, 56] 0
Conv2D-169 [[1, 24, 56, 56]] [1, 144, 56, 56] 3,456
BatchNorm2D-116 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-7 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-170 [[1, 144, 56, 56]] [1, 144, 28, 28] 1,296
BatchNorm2D-117 [[1, 144, 28, 28]] [1, 144, 28, 28] 576
ReLU6-8 [[1, 144, 28, 28]] [1, 144, 28, 28] 0
Conv2D-171 [[1, 144, 28, 28]] [1, 32, 28, 28] 4,608
BatchNorm2D-118 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
InvertedResidual-4 [[1, 24, 56, 56]] [1, 32, 28, 28] 0
Conv2D-172 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-119 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-9 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-173 [[1, 192, 28, 28]] [1, 192, 28, 28] 1,728
BatchNorm2D-120 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-10 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-174 [[1, 192, 28, 28]] [1, 32, 28, 28] 6,144
BatchNorm2D-121 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
InvertedResidual-5 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
Conv2D-175 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-122 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-11 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-176 [[1, 192, 28, 28]] [1, 192, 28, 28] 1,728
BatchNorm2D-123 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-12 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-177 [[1, 192, 28, 28]] [1, 32, 28, 28] 6,144
BatchNorm2D-124 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
InvertedResidual-6 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
Conv2D-178 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-125 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-13 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-179 [[1, 192, 28, 28]] [1, 192, 14, 14] 1,728
BatchNorm2D-126 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU6-14 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-180 [[1, 192, 14, 14]] [1, 64, 14, 14] 12,288
BatchNorm2D-127 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-7 [[1, 32, 28, 28]] [1, 64, 14, 14] 0
Conv2D-181 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-128 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-15 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-182 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-129 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-16 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-183 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-130 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-8 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-184 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-131 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-17 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-185 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-132 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-18 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-186 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-133 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-9 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-187 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-134 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-19 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-188 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-135 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-20 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-189 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-136 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
InvertedResidual-10 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-190 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-137 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-21 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-191 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-138 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-22 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-192 [[1, 384, 14, 14]] [1, 96, 14, 14] 36,864
BatchNorm2D-139 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
InvertedResidual-11 [[1, 64, 14, 14]] [1, 96, 14, 14] 0
Conv2D-193 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-140 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-23 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-194 [[1, 576, 14, 14]] [1, 576, 14, 14] 5,184
BatchNorm2D-141 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-24 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-195 [[1, 576, 14, 14]] [1, 96, 14, 14] 55,296
BatchNorm2D-142 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
InvertedResidual-12 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
Conv2D-196 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-143 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-25 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-197 [[1, 576, 14, 14]] [1, 576, 14, 14] 5,184
BatchNorm2D-144 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-26 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-198 [[1, 576, 14, 14]] [1, 96, 14, 14] 55,296
BatchNorm2D-145 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
InvertedResidual-13 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
Conv2D-199 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-146 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-27 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-200 [[1, 576, 14, 14]] [1, 576, 7, 7] 5,184
BatchNorm2D-147 [[1, 576, 7, 7]] [1, 576, 7, 7] 2,304
ReLU6-28 [[1, 576, 7, 7]] [1, 576, 7, 7] 0
Conv2D-201 [[1, 576, 7, 7]] [1, 160, 7, 7] 92,160
BatchNorm2D-148 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
InvertedResidual-14 [[1, 96, 14, 14]] [1, 160, 7, 7] 0
Conv2D-202 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-149 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-29 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-203 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-150 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-30 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-204 [[1, 960, 7, 7]] [1, 160, 7, 7] 153,600
BatchNorm2D-151 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
InvertedResidual-15 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
Conv2D-205 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-152 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-31 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-206 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-153 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-32 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-207 [[1, 960, 7, 7]] [1, 160, 7, 7] 153,600
BatchNorm2D-154 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
InvertedResidual-16 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
Conv2D-208 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-155 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-33 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-209 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-156 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-34 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-210 [[1, 960, 7, 7]] [1, 320, 7, 7] 307,200
BatchNorm2D-157 [[1, 320, 7, 7]] [1, 320, 7, 7] 1,280
InvertedResidual-17 [[1, 160, 7, 7]] [1, 320, 7, 7] 0
Conv2D-211 [[1, 320, 7, 7]] [1, 1280, 7, 7] 409,600
BatchNorm2D-158 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 5,120
ReLU6-35 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 0
AdaptiveAvgPool2D-3 [[1, 1280, 7, 7]] [1, 1280, 1, 1] 0
Dropout-1 [[1, 1280]] [1, 1280] 0
Linear-4 [[1, 1280]] [1, 12] 15,372
===============================================================================
Total params: 2,273,356
Trainable params: 2,205,132
Non-trainable params: 68,224
-------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 152.87
Params size (MB): 8.67
Estimated Total Size (MB): 162.12
-------------------------------------------------------------------------------
{'total_params': 2273356, 'trainable_params': 2205132}
|