paddle2.0高层API快速实现LeNet(MNIST手写数字识别)
[toc]
『深度学习 7 日打卡营·快速入门特辑』
零基础解锁深度学习神器飞桨框架高层 API,七天时间助你掌握 CV、NLP 领域最火模型及应用。
- 课程地址
传送门:https://aistudio.baidu.com/aistudio/course/introduce/6771
- 目标
- 掌握深度学习常用模型基础知识
- 熟练掌握一种国产开源深度学习框架
- 具备独立完成相关深度学习任务的能力
- 能用所学为 AI 加一份年味
DL 万能公式

1 | import paddle |
1 | '2.0.0' |
数据加载和预处理
1 | import paddle.vision.transforms as T |
1 | 训练集样本量:60000,验证集样本量:10000 |
查看数据
1 | %matplotlib inline |

1 | label: [5] |
搭建 LeNet-5 卷积神经网络
选用 LeNet-5 网络结构。
LeNet-5 模型源于论文“LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.”,
论文地址:https://ieeexplore.ieee.org/document/726791

每个阶段用到的 Layer

1 | # 网络搭建 |
网络模型可视化
1 | # 模型封装 |
1 | --------------------------------------------------------------------------- |
模型配置
- 优化器:SGD
- 损失函数:交叉熵(cross entropy)
- 评估指标:Accuracy
1 | # 配置优化器,损失函数,评估指标 |
1 | The loss value printed in the log is the current step, and the metric is the average value of previous step. |
模型评估
1 | result = model.evaluate(eval_dataset, verbose=1) |
1 | Eval begin... |
模型预测
批量预测
使用model.predit接口完成对大量数据集的批量预测
1 | result = model.predict(eval_dataset) |
1 | Predict begin... |

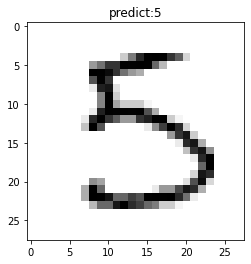


单张图片预测
采用model.predict_batch来进行单张或者少量多张图片的预测。
1 | # 读取单张图片 |
1 | [array([[-3.4706905, -6.674865 , -1.9018929, 3.8094432, -5.66697 , |

部署上线
保存模型
1 | model.save('finetuning/mnist', training=True) |
继续调优训练
1 | from paddle.static import InputSpec |
1 | The loss value printed in the log is the current step, and the metric is the average value of previous step. |
保存预测模型
1 | model_2.save('./infer/mnist', training=False) |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Comment
ValineDisqus



